
Years before the JSTOR scraping project that led to Aaron Swartz's indictment on federal hacking charges—and perhaps to his suicide—the open-data activist scraped documents from PACER, the federal judiciary's paywalled website for public access to court records. (The acronym PACER stands for Public Access to Court Electronic Records, which may sound like it's straight out of 1988 because it is.) Swartz got 2.7 million documents before the courts detected his downloads and blocked access. The case was referred to the FBI, which investigated Swartz's actions but declined to prosecute him.
A key figure in Swartz's PACER effort was Steve Schultze, now a researcher at Princeton's Center for Information Technology Policy. Schultze recruited Swartz to the PACER fight and wrote the Perl script Swartz modified and then used to scrape the site.
Until recently, Schultze has been quiet about his role in Swartz's PACER scraping caper. But Swartz's death inspired Schultze to speak out. In a recent phone interview, Schultze described how Swartz downloaded gigabytes of PACER data and how that data has been put to use throughout the last four years. Schultze told us he hopes the outrage over Swartz's death will provide momentum for legislation to finish the job Swartz and Schultze started almost five years ago: tearing down PACER's paywall.
In the interest of full disclosure: Schultze and I were colleagues at Princeton while I was in grad school there from 2009 to 2011. With another Princeton graduate student, Harlan Yu, we created RECAP, a Firefox extension that helps PACER users share documents they purchase both with each other and the public. And Carl Malamud, who played a key role in our story, provided financial support for some of my PACER-related research during this period.
The thumb drive corps

The documents in PACER—motions, legal briefs, scheduling orders, and the like—are public records. Most of these documents are free of copyright restrictions, yet the courts charge hefty fees for access. Even as the costs of storage and bandwidth have declined over the last decade, PACER fees have risen from seven to 10 cents per page.
Facing criticism that high fees limit public access, the US courts announced a pilot project in 2007 to provide free PACER access to users at 17 libraries around the country. Schultze and other open government activists saw the announcement as an opportunity to liberate documents from the PACER system.
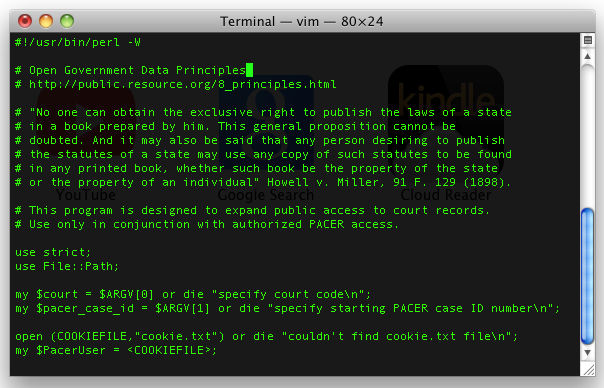
Schultze began working on a Perl script to automate the process of downloading documents from PACER. He envisioned a "thumb drive corps" of volunteers going into libraries, plugging in thumb drives containing his script (packaged as a Windows executable), and using the library's free access to download millions of PACER documents.
Schultze developed and tested the script using a personal PACER account, paying for every document he downloaded. The nearest library participating in the PACER program was more than a hundred miles from his home in the Boston area, so he would need help from volunteers around the country to put the plan into action.
In the summer of 2008, Schultze told Swartz, also in the Boston area at the time, about the PACER scraping scheme. "He said what Aaron would always say: 'show me the code,'" Schultze told Ars. "So I showed him the code. He said, 'Oh, I don't really like Perl. I'm not a Perl programmer.' Then he took my Perl code and made a whole bunch of great improvements."
“This is not how we do things”
Schultze and Swartz conferred with open government advocate Carl Malamud, who offered to provide server space to store the gigabytes of data they hoped to liberate. For the documents to be useful, they needed to capture not only the PDFs themselves but also docket files that contain key metadata such as filing dates and document descriptions.
In early September, Swartz e-mailed Malamud to discuss an alternative approach: instead of sending volunteers to libraries, they could crawl PACER directly from Malamud's server. Malamud was skeptical. "The thumb drive corps is based on going to the library and using their access," he noted. "Do you have some kind of magic account or something?"
Swartz asked a friend to go to a Sacramento library that was participating in the program. After the librarian logged the friend into the library's PACER account, the friend extracted an authentication cookie set by the PACER site. Because this cookie wasn't tied to any specific IP address, it allowed access to the library's PACER account from anywhere on the Internet. But Swartz admitted to Malamud that he didn't have the library's permission to use this cookie for off-site scraping.
"This is not how we do things," Malamud scolded in a September 4 e-mail. "We don't cut corners, we belly up to the bar and get permission."
"Fair enough," Swartz replied. "Stephen is building a team to go to the library."
But without telling Malamud or Schultze, Swartz pushed forward with his offsite scraping plan. Rather than using Malamud's server, he began crawling PACER from Amazon cloud servers.
"I thought at the time he was actually in the libraries" downloading the documents that were accumulating on his server, Malamud told Ars in a phone interview. In reality, Swartz merely had to dispatch a volunteer to the library once a week to get a fresh authentication cookie. Swartz could do the rest of the work from the comfort of his apartment.
Access denied
It took a while for the courts to figure out what was happening. "The way the library trial was set up was that the courts would continue to track usage but would simply never bill the libraries for the usage that occurred," Schultze told us.
Swartz started his downloading in early September. On September 29, court administrators noticed the Sacramento library racked up a $1.5 million bill. The feds shut down the library's account.
"I thought at the time he was actually in the libraries."
"Apparently PACER access at the main library I was crawling from has been shut down, presumably because of the crawl," Swartz told Schultze and Malamud in an e-mail that day.
The courts issued a vague statement about suspending the program "pending an evaluation." A few weeks later, a court official revealed law enforcement had been called to investigate the suspected security breach. Malamud told us that after Swartz fessed up, Malamud grilled him to understand whether any laws had been broken. Malamud believes the fact that neither PACER nor the library had terms of service prohibiting offsite downloading made it likely Swartz's actions were within the law.
Malamud thought they would be in an even stronger position if they could demonstrate the value of the data Swartz extracted, so he began an intensive privacy audit. For most of October, Malamud worked around the clock searching for documents containing Social Security numbers and other sensitive information. Out of the 2.7 million documents Swartz downloaded—about 700GB of data in all—Malamud discovered about 1,600 with privacy issues. He then sent a report to court administrators disclosing the poorly redacted documents he had found and encouraging the courts to examine the rest of the documents in PACER to ferret out similar privacy problems.
Malamud and Swartz wanted to tell their side of the story to the public, so they began talking to a reporter at the New York Times. The result was an article in February 2009 explaining the issue and Swartz's actions.
"This was part of how Aaron approached things," Schultze told us. His PACER activities were "a project to liberate the documents but also an effort to make public the problems that existed to hopefully solve the larger policy problem."
Both the FBI and the Department of Justice investigated the case. They identified Swartz via his ownership of the Amazon servers used to crawl PACER. Both agencies dropped the case by April 2009. Later that year, Swartz made an open records request for his own FBI file and gleefully posted it online, calling it "truly delightful."
reader comments
153